Estudo de Caso
Stack de Observabilidade
Stack de Observabilidade
Plataforma reproduzível de métricas, logs e alertas para reduzir MTTR, aumentar visibilidade operacional e tornar a resposta a incidentes mais orientada por dados
Introdução
Em muitos ambientes, a operação consegue colocar serviços no ar, mas ainda não consegue enxergá-los com clareza quando algo sai do esperado. A aplicação responde, os containers sobem, o deploy acontece, mas a equipe continua dependente de verificações manuais, leitura isolada de logs e investigação reativa para entender falhas, lentidão ou comportamento anômalo. Esse é um problema comum em operações com baixa maturidade de observabilidade.
Este projeto foi criado para atacar exatamente essa lacuna. A proposta não era apenas subir ferramentas conhecidas do ecossistema open source, mas montar uma stack coerente de observabilidade, capaz de coletar métricas, centralizar logs estruturados, exibir dashboards operacionais e disparar alertas automáticos. Em vez de sinais dispersos, a solução busca criar capacidade real de operação: detectar, investigar e responder com mais velocidade e menos improviso.
Problema de negócio
Sem observabilidade estruturada, a equipe perde tempo demais tentando descobrir o que aconteceu. Falhas são percebidas tarde, logs ficam espalhados, a investigação começa do zero a cada incidente e decisões técnicas passam a depender mais de percepção do que de evidência. Esse cenário aumenta o esforço humano, reduz previsibilidade e compromete a confiabilidade dos serviços.
Do ponto de vista operacional, o impacto mais direto aparece no MTTR. Quando não há métricas acessíveis, logs centralizados e alertas automáticos, o tempo para detectar, diagnosticar e reagir aumenta. O problema deixa de ser apenas técnico e passa a afetar produtividade, estabilidade do ambiente e capacidade da equipe de sustentar serviços com método.
Solução que entrega
A solução foi desenhada como uma stack de observabilidade executada em ambiente local/containerizado, composta por Prometheus, Grafana, Loki, Promtail, Node Exporter e integração com Slack. Essa combinação permite cobrir o fluxo completo de observabilidade: coleta de métricas, centralização de logs, visualização operacional e resposta automatizada a eventos críticos.
A arquitetura parte de uma aplicação simples que gera logs estruturados em JSON. O Promtail coleta esses eventos, aplica labels e os envia ao Loki. Em paralelo, o Node Exporter expõe métricas de infraestrutura, como uso de CPU, para o Prometheus realizar scrape periódico. O Grafana consome tanto o Loki quanto o Prometheus, consolidando métricas e logs em dashboards e regras de alerta. Quando uma condição crítica é atendida, a notificação segue para o Slack.
Com isso, o projeto entrega uma base observável de ponta a ponta: não apenas coleta sinais, mas organiza esses sinais de forma útil para troubleshooting, leitura operacional e reação rápida a incidentes.
Como o projeto melhora a vida da empresa
O primeiro benefício está na visibilidade operacional. Em vez de depender de acesso manual a arquivos locais ou conferências pontuais, a equipe passa a ter métricas e logs centralizados em uma mesma interface. Isso torna muito mais fácil entender o estado do ambiente, identificar degradações e localizar erros recentes.
O segundo benefício está na redução do MTTR. Quando métricas mostram que há um problema, logs ajudam a explicar qual problema ocorreu, dashboards oferecem contexto e alertas acionam a equipe no momento certo. Essa integração encurta o caminho entre incidente e diagnóstico, reduz investigação cega e melhora a velocidade de resposta.
O terceiro benefício está na produtividade operacional. Parte do tempo que seria gasto em troubleshooting manual, coleta dispersa de evidências e reexecução de testes passa a ser substituída por leitura orientada de dashboards, consultas LogQL e PromQL e regras automáticas de alerta. Isso libera a equipe para atuar com mais foco em causa raiz e melhoria contínua.
Há ainda um ganho importante de confiabilidade e governança técnica. Com uma stack reproduzível, documentação clara e critérios explícitos de aceite, a operação deixa de tratar observabilidade como adorno e passa a tratá-la como parte da sustentação do serviço. Isso fortalece a base para evoluções futuras em monitoramento, confiabilidade e maturidade DevOps/SRE.
Fluxo da solução
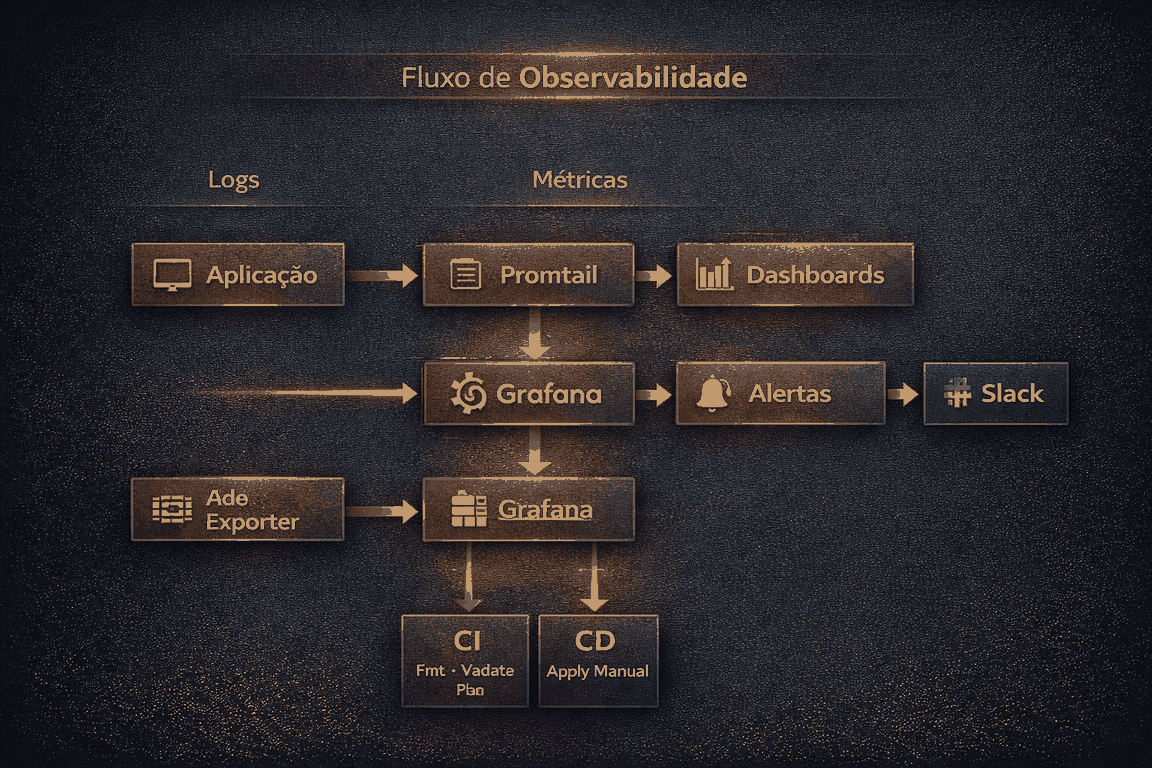
O fluxo principal da solução foi desenhado para ser claro e funcional.
Decisões de arquitetura
Uma decisão central foi adotar logs estruturados em JSON como fonte principal de observabilidade. Isso aumenta o valor das consultas, facilita filtros por severidade e torna os alertas mais explicáveis. Em vez de mensagens soltas de debug, o projeto passa a trabalhar com eventos operacionais úteis para investigação.
Outra escolha importante foi usar Docker Compose como base de execução. Isso garante reprodutibilidade local, reduz atrito para validação e mantém a stack simples o suficiente para portfólio, sem perder a coerência operacional do fluxo. A solução não tenta simular alta disponibilidade ou complexidade desnecessária cedo demais; ela foca em um MVP forte e validável.
Também foi relevante centralizar a operação no Grafana. Em vez de usar interfaces dispersas para cada componente, o Grafana concentra dashboards, exploração de logs e alertas em um único ponto de leitura e resposta. Isso fortalece a narrativa do projeto porque aproxima a stack de uma rotina real de operação.
Por fim, o recorte técnico adotado foi proposital: começar com CPU como métrica principal e erro de aplicação como alerta principal. Essa delimitação evita inflar o escopo cedo demais e cria um MVP equilibrado, cobrindo métrica, log, dashboard e alerta de forma didática e operacionalmente útil.
Indicadores que fazem sentido acompanhar
Os indicadores mais coerentes para avaliar o sucesso dessa solução são:
- tempo médio para detectar erro de aplicação;
- tempo médio para localizar a causa inicial de um incidente;
- quantidade de erros identificados por janela de tempo;
- tempo de resposta entre evento crítico e alerta enviado;
- frequência de picos de CPU e sua correlação com erros;
- taxa de sucesso na consulta de logs em tempo real;
- disponibilidade dos componentes da própria stack de observabilidade;
- redução do esforço manual para troubleshooting em relação ao cenário sem observabilidade estruturada.
Esses indicadores fazem sentido porque medem não apenas coleta de dados, mas a utilidade real da stack para operação, diagnóstico e confiabilidade.
Resultado do case
O resultado esperado deste case é a consolidação de uma stack de observabilidade reproduzível, com capacidade de coletar métricas, centralizar logs estruturados, exibir dashboards operacionais e disparar alertas automáticos no Slack. Mesmo ainda em evolução de fases, o projeto já demonstra uma direção arquitetural clara e um recorte técnico bem definido, conectando visibilidade, troubleshooting e resposta a incidentes em um mesmo fluxo.
Em termos de reprodutibilidade, o valor do projeto está em organizar a stack de forma containerizada, documentada e validável. Isso cria uma base que pode ser montada, inspecionada e evoluída com menos improviso, tornando observabilidade algo replicável e não dependente de configuração ad hoc.
Em produtividade operacional, o ganho vem da substituição de investigação manual e dispersa por uma leitura integrada de métricas e logs. Com isso, a equipe tende a gastar menos tempo procurando evidências e mais tempo entendendo o incidente e decidindo a ação correta. Esse ponto é especialmente importante porque reduz atrito no dia a dia e profissionaliza a rotina de troubleshooting.
Em confiabilidade, o case cria base para uma operação mais rápida e orientada por dados. A integração entre Prometheus, Loki, Grafana, Promtail e Slack transforma sinais isolados em capacidade operacional utilizável: detectar mais cedo, diagnosticar com mais contexto e reagir com menos esforço manual. Isso fortalece diretamente a redução de MTTR e a sustentação do serviço.